わたしたちのチームでは顧客からの声を集めた「ニーズカウンター」をベースに開発の優先順位を決めてアジャイル開発をしています。
「こういう機能がほしい!」といった要望はニーズカウンターにあがってきますが、「表示に時間がかかる」や「この操作を行うとたびたびエラーになる」などの非機能要件は要望としてほとんどあがってこないため、どうしても開発の優先度が低く、後回しになってしまいがちです。
ユーザーから「表示が遅い」などの報告を直接いただくこともありますが、そういった報告をうける前に手を打っておくことで、ユーザーが当たり前にもとめる品質を提供し続けられると考えています。
目次
そもそも非機能要件とは?
そもそも非機能要件はどんなものでしょうか。非機能要件はIPAによる「非機能要求グレード2018」に「非機能要求グレードの6大項目」として定義されています。この非機能要求グレードはよくまとまっており、自分たちが提供しているサービスがどの程度のレベルを満たしているかを確認するのにも役立ちます。SaaSサービスを提供していると顧客からセキュリティチェックシートへの回答を求められることもありますが、そのときの判断基準としても使えます。
サービスやチームの状況、コスト的な面からすべてを最初から網羅するのは現実的ではありません。しかし現状を把握しておくことで、ビジネス上の目標と照らし合わせながら「来年はここをこのレベルにまで持っていきたい」や「来月はここを強化する」と開発スケジュールに組み込んでいきやすくなります。
それでは非機能要求グレードの6大項目とともにわたしたちがおこなっている具体的なとりくみをご紹介します。
可用性
システムサービスを継続的に利用可能とするための要求。
稼働時間・停止時間などの運用スケジュール、障害、災害時における稼働目標としての要求があげられます。具体的には冗長化対応やバックアップを取ることで実現します。また障害時の復旧・回復方法および体制を確立することで対応します。
わたしたちのとりくみ
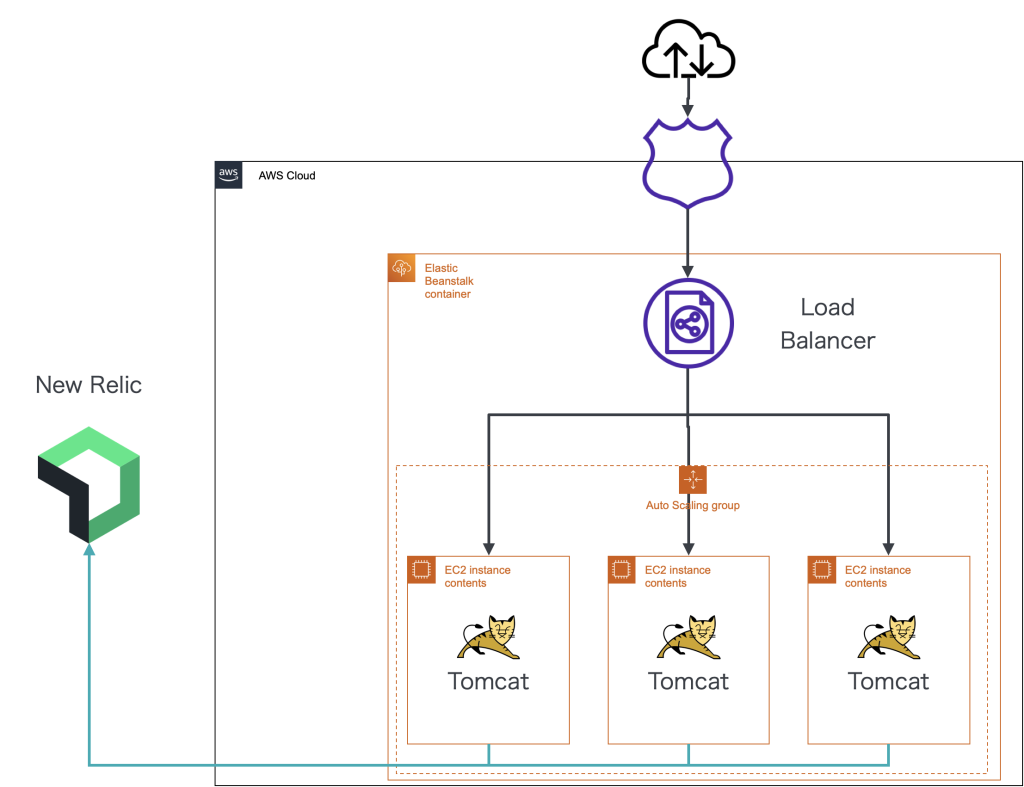
EC2とRDSによる冗長化構成にすることで可用性を高めています。詳しい構成についてはこちらのブログで紹介しています。
またメンテナンス時間を設けずにアップーデートができるよう、Beanstalkを使ったBlue/Green デプロイをしています。
バックアップも1日1回フルバックアップを実施し、日次・週次・月次による世代管理をすることで障害時の復旧体制を整えています。
性能・拡張性
システムの性能、および将来のシステム拡張に関する要求。
システムとしてどの程度の性能が求められるのか、将来的にはどれくらいの拡張が見込まれるのか、ピーク時、通常時などシステムの特性にあわせた性能の要求があげられます。具体的には性能目標値を意識したインフラの設計、将来へ向けたキャパシティプランニングをすることで実現します。
わたしたちのとりくみ
優先的に対応していきたいものの、機能開発が優先されてしまってなかなか手をつけられない、というのはここに分類されるものになってくるかと思います。いくつかの準備によって日々の開発で対応していける体制を整えました。のちほど詳しく紹介します。
運用・保守性
システムの運用と保守のサービスに関する要求。
運用中に求められるシステム稼働レベルや問題発生時の対応レベルなどが含まれます。具体的には監視手段およびバックアップ方法の確立、問題発生時の役割分担、体制、訓練、マニュアルの整備によって実現します。
わたしたちのとりくみ
サーバーの負荷に対する監視、アプリケーションの問題に対する監視を行うとともに障害発生時の対応フローを構築しておくことで対策をとっています。
移行性
現行システム資産の移行に関する要求。
新システムへの移行期間および移行方法、移行対象の種類および移行量が求められます。具体的には移行スケジュールの立案、移行ツールの開発や移行体制の確立、移行リハーサルの実施により実現します。
わたしたちのとりくみ
SaaSサービスだと移行性について意識することはあまりないかもしれませんが、例えばデータのインポート機能や一括登録機能を用意しておくことで顧客がサービスを利用開始するときに移行しやすくするといった対策を取ることができます。
AWSのEC2やRDSのインスタンスファミリーを新しいものに変更する場合のようにインフラ構成を変えることも新システムへの移行と考えられるため、その際の移行手順の確認やリハーサル、万が一のときのリカバリープランを用意しておくことで対応しています。
セキュリティ
情報システムの安全性の確保に関する要求。
利用制限や不正アクセスの防止が求められます。具体的にはアクセス制限、データの秘匿や不正の追跡、監視、検知、運用員への情報セキュリティ教育により対応します。
わたしたちのとりくみ
AWSの基本的なセキュリティの考え方として責任共有モデルがあります。これは「AWSのクラウドのセキュリティに対する責任」と「利用者のクラウド内のセキュリティに対する責任」とを分けることで責任範囲を明確にするモデルです。
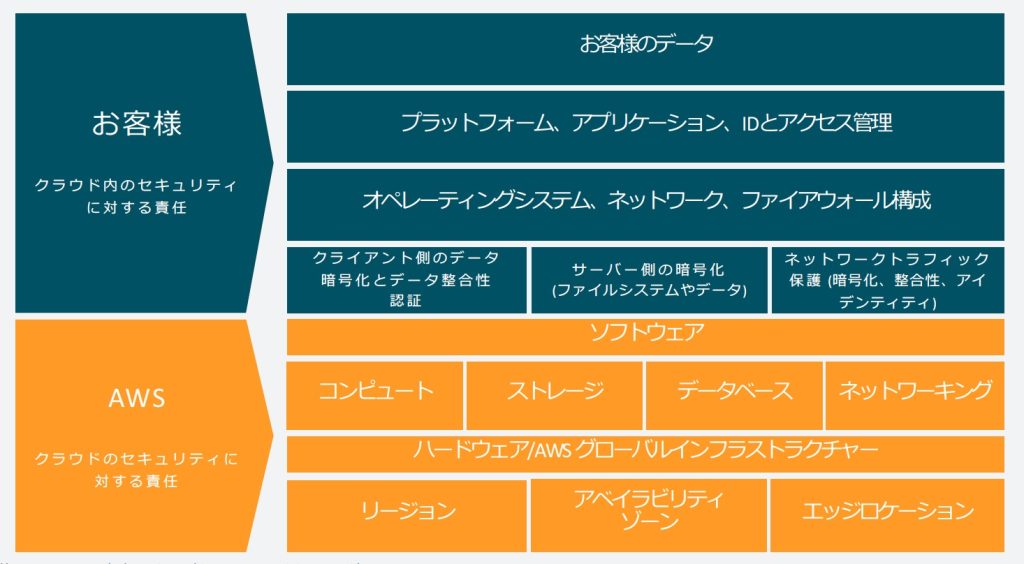
この考え方にそって、
- WAFの導入などの長期的な視点でのとりくみ
- OS/ミドルウェアのパッチの適用やアプリケーションをセキュアに実装するなどの日々のとりくみ
という両方の視点で対策をしています。
システム環境・エコロジー
システムの設置環境やエコロジーに関する要求。
耐震/免震、重量/空間、温度/湿度、騒音など、システム環境に関する事項、CO2排出量や消費エネルギーなどエコロジーに関する事項が求められます。具体的には規格や電気設備にあった機器の選別や環境負荷を低減させる構成により対応します。
わたしたちのとりくみ
例えばAWSでは二酸化炭素排出量を削減するためにこのような取り組みを行っています。
https://sustainability.aboutamazon.com/environment/carbon-footprint
自分たちでできるとりくみとしてはAWSのオートスケーリング機能を使うことでアクセスに応じて最適なリソース調整ができます。toB向けのSaaSの場合、平日の日中のアクセスがほとんどのため、比較的アクセスの少ない夜間や休日のリソースを減らすことでコストダウンにもつながります。
性能の改善に取り組むために
以前のわたしたちは機能開発を優先して性能の改善に取り組むことができていませんでした。サーバーの負荷は監視していたので「新しく作った機能のパフォーマンスがあまり良くなさそう」という感覚はあったものの、具体的な数字は把握できておらずそのままになっていました。
性能の劣化はサーバーのスペックをあげてカバーするという運用をしていましたが、それも限界があり本腰を入れて改善に取り組むことにしました。
推測するな、計測せよ
性能に問題がある、という肌感覚はあったものの何から手をつけるべきかわからなかったので、まずは今の状態を計測するところからはじめました。
わたしたちのアプリケーションはTomcat上で動かしています。AWSのオートスケーリング機能を使って複数台のTomcatが動いていますが、ログをCloudWatchLogsに集約してメトリクスフィルターを設定することで計測しています。
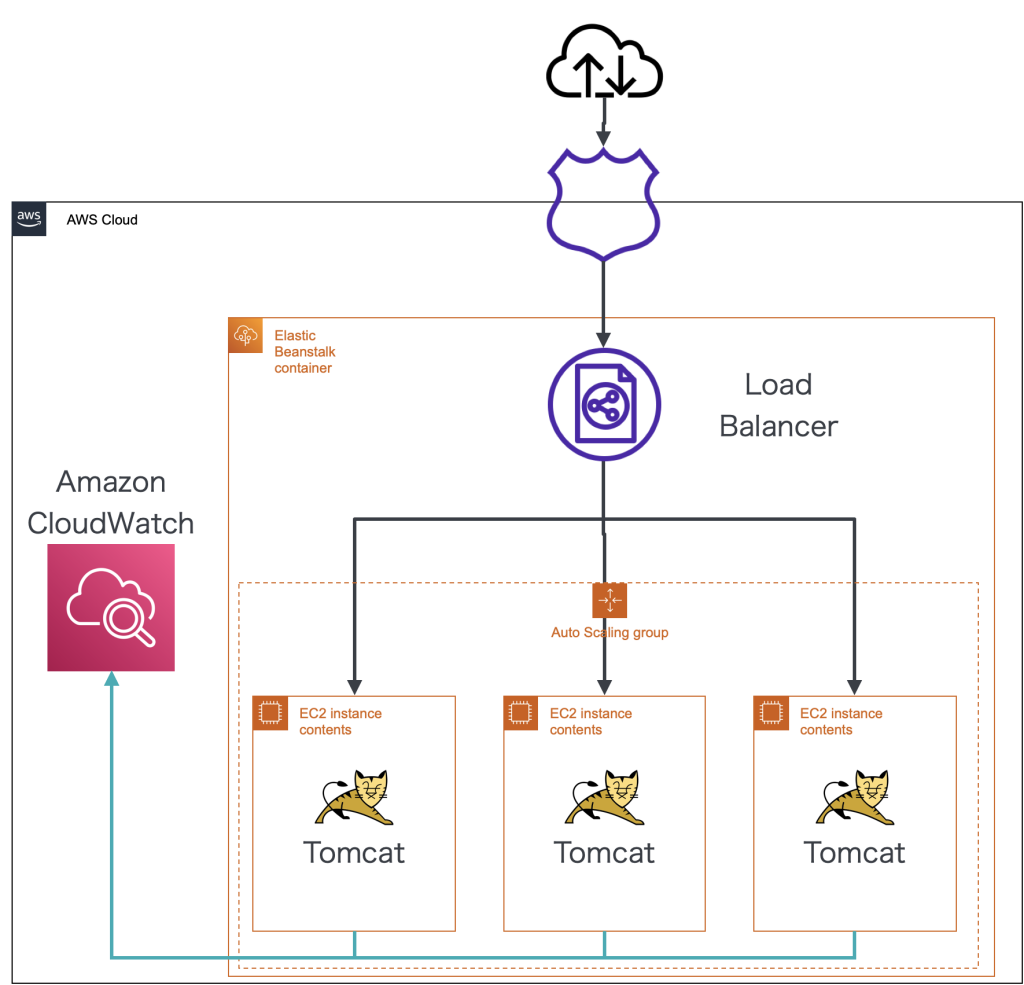
主要なException数
アプリケーションのログに含まれるNullPointerExceptionをはじめ主要なExceptionの数を計測しています。Exceptionが起きているということは処理が正常に完了していないため、ユーザーにはエラーが表示されています。今までログを確認して必要に応じてプログラムを修正することはしていましたが、どれくらいエラーが起きているか総数を把握するためにExceptionの数を計測するようにしました。
404 not foundなどクライアント側のリクエストに問題がある場合もExceptionを吐くため、それらは集計から除外しています。
データベースのトランザクションエラーにまつわるException数
データベースのトランザクションエラーが発生するということは、ユーザーにとっては登録・編集・削除がうまく完了しなかった、あるいはデータの取得に失敗しています。
アプリケーションの特性上データベースへのアクセス頻度が高く、問題が発生することも多かったため個別に計測するようにしました。
5xxエラー率
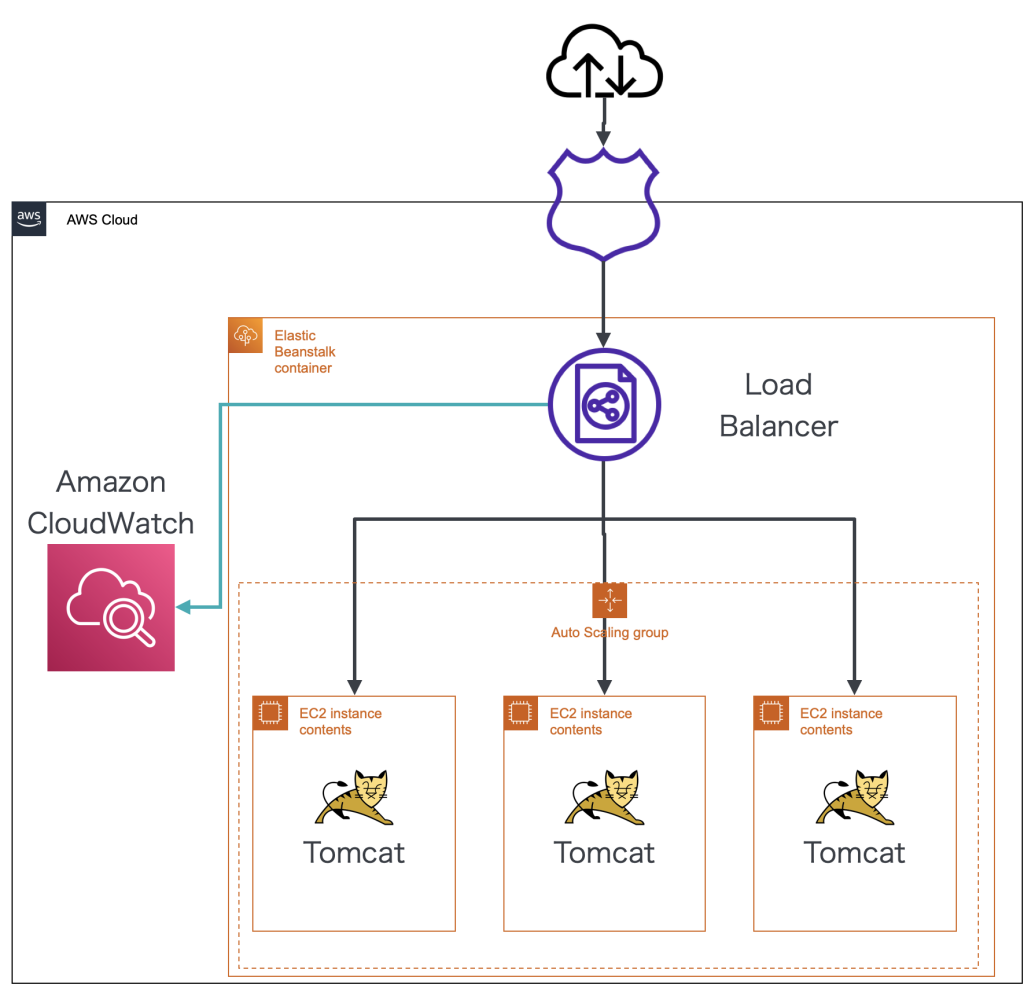
Exceptionの数だけではリクエスト全体におけるエラーの割合を把握するのが難しいため、ロードバランサーがEC2インスタンスから5xxレスポンスを受け取った割合をCloudWatchを使って計測しています。これによりリクエスト全体におけるエラーの割合が確認できます。
NewRelicによるSQLのパフォーマンス
サーバー監視サービスのNewRelicを使ってそれぞれのSQLのボトルネックを把握できるようにしました。実行に時間がかかる重たいクエリ、実行にそれほど時間はかかっていないものの発行回数が多いクエリがわかるようになりました。
わたしたちの場合、ウェブアプリケーションのレスポンスタイムの大半を占めるのはデータベースアクセス部分のため、SQLの実行時間の改善がそのままパフォーマンスの改善につながります。
NewRelicを使うことでSQLのボトルネックとそれがどこのコードから呼び出されているかがわかるため、修正が必要な箇所をすぐに把握できます。NewRelicではJVMも確認できるので、メモリやガベージコレクションの状態も見てEC2のインスタンスタイプを調整しています。
Lighthouseによるスコア
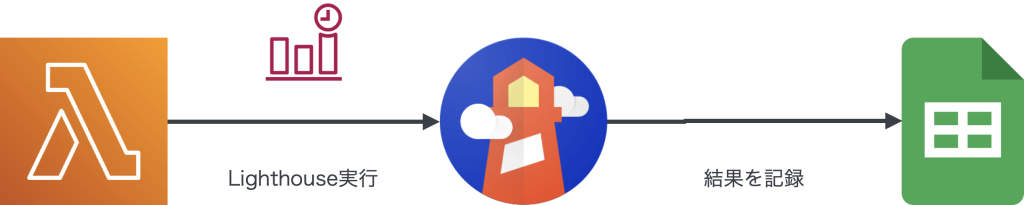
リクエストごとのパフォーマンスはサーバーサイドで確認できますが、ユーザーが画面を開いたときには複数のリクエストが走っています。よりユーザーの体感に近いパフォーマンスをはかるため、Lighthouseを使って計測しています。1時間に1回LambdaからChromiumをヘッドレスで起動してLighthouseを実行して結果のPerformance、FirstContentfulPaint、LargestContentfulPaintをスプレッドシートに記録しています。
目標やしきい値を決めて改善する
上であげた数字を毎日計測し、重要なところから目標を立てて改善を進めています。目標とする数字の妥当性は難しく、どこまでやればゴールかはまだ試行錯誤の途中です。ただ今まで数字としてみていなかったため、すぐに改善につながる対策も多くそれなりの効果が出ています。スクラム開発の1スプリントを性能改善につぎ込むのではなく、1スプリントの中の1タスクでできるボリュームからとりくみ始めています。
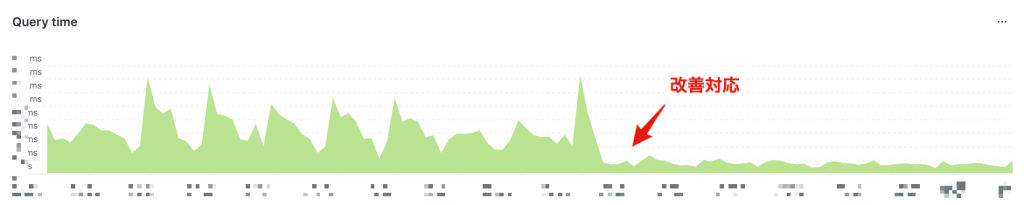
例えばindexを適切にはることでSQLの実行時間を短縮する、SQLのリトライ機構を取り入れることでトランザクションエラーを減らすといったかたちです。

こまかな施策をやりきると大規模なリファクタリングが必要なレベルの対応が残りますが、これも「SQLの実行時間がXXミリ秒以上かかるようになったらリファクタリングに着手する」のようにあらかじめ決めておくことで判断しやすくなります。
まとめ
開発優先順位の中に非機能要件の対応を入れるためには日々の監視、計測が非常に重要になります。
パフォーマンスが悪化したので手を打つ必要がある。その判断をするためには今の状況、目標はどこにあるのか、どのしきい値を超えたら対策する必要があるのかを明確にしておく必要があります。数字として見えるようにしておくことで対策の必要性をチームメンバーやステークホルダーと共通認識として持てます。
開発した機能の利用状況が攻めの数字だとすれば、性能の数字は守りの数字です。新しい機能を開発しても実際に利用されるかどうかはわかりません。いっぽうで性能改善は確実にユーザーの体験を良いものにしてくれます。両者のバランスをとりながら開発を進めていくことが重要だと考えています。
一緒に働く仲間を募集しています。
新卒採用・中途採用を問わず、年間を通して、さまざまな職種を募集しています。「すぐに仕事がしたい」「話を聞いてみたい」「オフィスを訪問してみたい」など、ご応募をお待ちしています。共に未来をカタチにする仲間を待っています。