
アジャイル開発をしていると、ひょっとしたら
「アプリケーションの機能を変えたら高負荷になってサイトが落ちた」
「サーバー増やしても全然サイトの応答が早くならない」
「いつの間にかマイナーな機能が死んでて放置されてた」
という状態に陥ってしまった方もいるのではないでしょうか?
我々もアジャイル導入初期ではリリースするごとにバグがどんどん増え、 サービスがどんどん重くなるという状況に陥ったことがあります。 開発、リリース、運用の体制を全然整えていないのに突っ走ったことが原因だったと考えています。 今回はアジャイル開発のためのAWSを活用した運用体制についてお話します。
アジャイルを支えるインフラ構成
リソースの柔軟性について
アジャイルでは「価値のあるアプリケーションを早く継続的に提供する」ことを前提としています。 日々機能が変わり続けていくためプロジェクトの初期と後期では機能が大きく変わっています。 そのためウォーターフォール型の開発のように事前に何のリソースをどの程度使うのか、といったサイジングをおこなう方法とは相性が悪いです。 アジャイルのインフラは必要になったときに柔軟にリソースを変更できる方が適していると思います。
WEB+DB構成の場合
例えばシンプルにWEBサーバー+DBサーバーで稼働しているサービスがあります。 これをAWSでアジャイルに適した形に変更するなら、WEBとDBのリソースを変動できる以下の構成になるかと考えています。
■WEB + DB
■ELB + WEB(EC2複数台)+ DB(RDSでリードレプリカ使用)
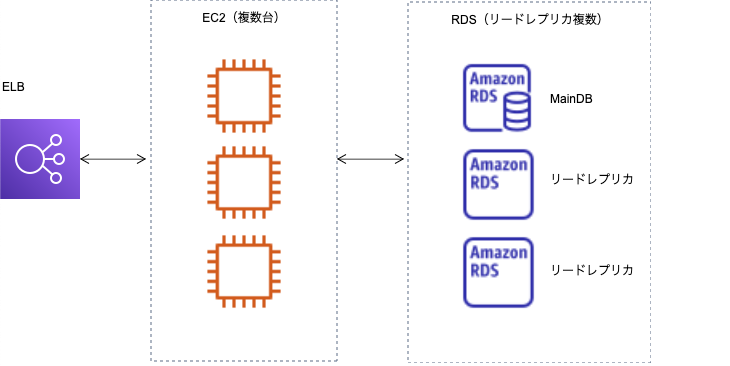
まずフロントをロードバランサーに変更し、WEBサーバーを複数配置可能にします。WEBサーバーは負荷状況によってスケールアウトできるようにします。可能であればオートスケールを使うと良いと思います。DBサーバーはリードレプリカを使い参照系処理をスケールアウトできるようにします。
こうすることでなるべくサービスをダウンをさせずにリソースを柔軟に変更できると思います。
役割の分散化について
ユーザーが少ない状態であれば上記のようなシンプルなWEB+DB構成でも問題はあまり出ないかと思いますが、 ユーザーが多くなってくると恐らくスケールアウトをしてもボトルネックが解消しづらい状況になってくると思います。 例えばWEBサーバーで、
- 静的コンテンツの配信
- アプリケーションの処理
- セッションの管理
- メール配信
- バッチ処理
といった役割を担っているとします。 上記でどれか一つでもボトルネックがでると重くなるため、WEBサーバーのスケールアウトやアップが必要になってしまいます。 DBのことを度外視すればスケールアップで性能を2倍にすれば「アプリケーションの処理」は2倍になりますが、 ネットワークやDISKIOが絡む部分は性能が上がらないのでそれ以外の部分は捌ける量が変わらない可能性が高いです。 効率よくボトルネックを解消するには役割に対して適切な対処方法が必要になってくるため、役割を分散させる方が効率が良くなってきます。
AWSのインフラサービスを使って役割とリスクを分散させる
AWSにおいて上記役割を分散させるとしたら例えば以下のような形があると考えています。
- 静的コンテンツの配信: CloudFront
- セッションの管理: DynamoDB
- メール配信: SES
- バッチ処理: Lambda or バッチ用のEC2
全体の構成としては以下になります。
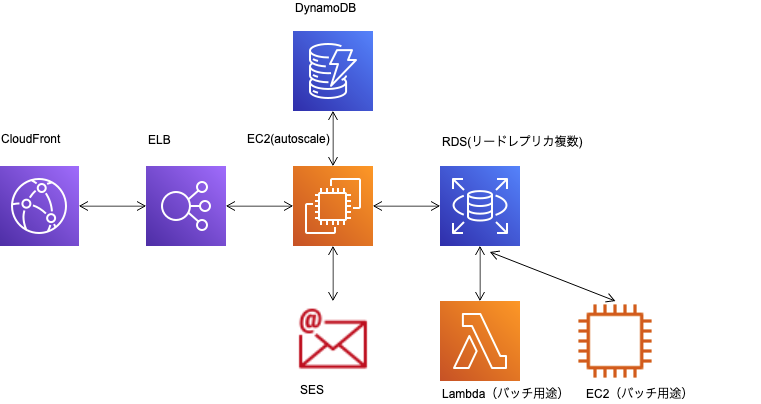
役割をわけることでどの部分に負荷がかかっているのか明確になります。 また、CloudFront、SES、DynamoDB(オンデマンド) は高負荷によるダウンがないため、 サービスダウンのリスクを減らす効果も期待できます。
アジャイルを支える監視
前述の通りアジャイルではアプリケーションのアップデートを頻繁におこないます。 バグや問題を出さずにリリースし続けることが理想ではありますが・・・、それはとても難しいです。 アジャイルではバグや問題が出ることを前提として、 問題発生を検知しすぐに対処できるようにしておくことが重要だと考えています。 そのための監視体制を用意しておきます。
アジャイルでは何を監視するか?
監視を適当に設定していると
「なんかアラート飛んできたけど対処するものなのかよくわからない」
「これって緊急なのかそうではないのかわからない」
「いつも飛んできてるけど問題ないから様子見」
ということになってしまいがちですよね? 何に対する監視なのか目的をはっきりさせておかないと、アクションを取ることが難しくなってしまうのかなと思います。 サービスによって必要な監視は変わってきますが、アジャイルではざっくり以下のようなものが必要になるのかと考えています。
負荷に対する監視
ここではアプリケーションの機能追加などによって発生する負荷増加に対する監視を目的とします。 アタックや突発的なアクセス集中は一旦置いといてください。
リソース監視
CPU使用率、サーバー台数などの監視になります。 リリースによって作りの問題からCPU使用率が急激に上がるといったことはよく発生します。 想定よりもオートスケールの台数が増えた場合はアプリケーションを見直した方が良いかもしれません。
設定について
リソース情報のメトリクスは基本的にはCloudWatchで用意されているため、そのまま使えると思います。
レイテンシの監視
サイトがレスポンスを返すまでにかかる時間の監視になります。 なるべくユーザーの使用感とデータを合わせたいので、ログイン後の画面やDBを使ったページへの監視を推奨します。 ユーザーの使用感に直接紐づく部分のため、アラートが出た場合はベースのサーバー台数を増やすなどで改善をおこなった方が良いと思います。
設定について
レイテンシのメトリクスはCloudWatchでは用意されていないため、以下のような対応が必要になりますのでご注意ください。
- 外部サービスを使う
- Lambdaでコードを書き、CloudWatchのカスタムメトリクスにデータを入れる
- EC2からcurlなどのコマンドを使い、CloudWatchのカスタムメトリクスにデータを入れる
アプリケーションの問題に対する監視
エラーレートの監視
レスポンスがどの程度200以外が返っているのかの監視になります。 アタックなどのリクエストにより400や500は必ず発生するためしきい値の設定は運用しながら設定する形になります。 不自然な上がり方をした場合はアプリケーションのバグの可能性があるため調査をした方が良いと思います。
設定について
CloudFrontやELBではHTTPステータスの各種メトリクスが用意されているので、そのまま使えるかと思います。
ログの監視
アプリケーションが出力するログや、WEBサーバーが出力するエラーログの監視になります。 アプリケーション側でエラーハンドリングを誠実に対応していれば「Fatal」「Error」など嫌なワードが出たときにアラートを飛ばす形にできるかと思います。 このアラートがリリース後に増えた場合、まずい問題が出ている可能性があるため調査することをお勧めします。
設定について
アプリケーションのログをCloudWatchLogsで収集し、メトリクスフィルターを使うことで特定文字が出たときにプロットすることが可能です。そのためある程度簡単に実装できるかと思います。
それ以外の監視
サービス運用上必要なものとして設定しておいた方が良いものを紹介します。
OS内部の監視
サービスの監視、プロセスの監視、DISK空き容量の監視など通常は問題の出ない部分の監視になります。 では必要ないのでは?と思うかもしれませんが、 ミドルウェアのバグによるサービスやプロセスのダウン、 プロセスクラッシュによるログ生成からのDISK逼迫など予想が難しい問題が出ることもあり、問題の検出のため入れておいた方が無難です。
設定について
カスタムメトリクスにプロットしても良いのですが、普段は使わないのでEC2内からcronなどで監視スクリプトを実行し、問題が出たときにアラートを通知するといった形でも問題ないと思います。
インフラ自体の問題の監視
インフラ自体に問題が出ているかどうかの監視になります。 AWSの障害ページの更新通知、AWSが用意しているインフラ関連の障害メトリクスの監視設定をする形になります。 AWSのサービスも年に数回ダウンを引き起こしますので、原因の特定を素早くするために監視を入れておいた方が良いかと思います。 なおインフラ障害の情報はTwitterなどエンドユーザーが発信する媒体が一番早いです。 アラートが出てしまった場合、何ができるかは状況次第になりますので事前に何か対策を用意するのは難しいです。
設定について
AWSサービス自体の障害の場合はAWSアカウントのroot宛にメールが通知されます。EC2やRDSなど個別のインスタンスの障害の通知については「StatusCheckFailed_System」といったメトリクスや、正常に稼働していれば常に値が出てくるメトリクスの「データ不足」をトリガーにする形になります。
インシデント体制
リリース方法や監視で気をつけていてもユーザーに影響を与えてしまうインシデントは発生してしまうものです。 そうなったときにすぐにアクションをできるように事前に用意をしておくと良いと思います。
ユーザーへすぐに障害通知できるようにしておく
実際にインシデントが発生してしまったときにまず行うことは、ユーザーに通知することかと思います。 ここで気をつけないといけないのは「障害時に障害報告ページが表示できない」という残念なことにならないようにすることです。 障害報告ページはAWSとは別でもつことをお勧めします。
素早くリリースの差し戻しをできるようにしておく
インシデントの根本的な対処はそれぞれ異なってくるかと思いますが、 リリースによる影響で問題が発生した場合は、指し戻すことを考慮しておくと良いです。 インシデントが出るのがリリース直後とは限らないので、 常に差し戻しのデプロイをすぐに実行できる状態を維持することをお勧めします。
アタックやアクセス殺到時の対応についてルールを用意しておく
アジャイルとは直接関係がありませんが、リクエストが急激に増えることによるサーバーの高負荷はよくあります。 アタックはAWSWAFなどでサーバーに到達する前にリクエストをカットする方が望ましいのですがアタックと判定されないリクエストも多くあります。 そのため基本的にはスケールアウトで凌ぐ形になるかと思いますが、設定上限を超えてしまったときにどうするのかはルールを定めておいた方が良いです。 というのも決済権をもつ人とコンタクトして決めていたら対応が長引くからです。
利用状況の計測
アジャイルの目的のところでもお話したところですが、 アジャイルは「顧客にとってのアウトカム(成果)を最大化する」のが目標ですので、 ユーザーが実際に何を使っているのか知ることはとても重要だと考えています。 使われていない機能を強化するようなことは避けたいですし、リリースした機能が使われているかどうか常にチェックしたいです。
利用状況を測るツールを使う
サービスのどこが使われているのか一番簡単に知ることができるのはGoogleAnalyticsなどのアクセス解析ツールかと思います。 ページ遷移、クリックなどの状態遷移(フロントエンド側)を取得することができますので、まずはここから始めるのが良いのかと思います。 アクセス解析ツールのデータだけではユーザーの利用状況がうまく取れないのであれば、 MixPanelなどのユーザーの行動をより深く取れるグロースハックツールを使うのも良いと思います。
より詳細を欲しくなった場合
ユーザーの行動の詳細がより必要な場合、 上記ツールでは難しくなってくることもあります。
例えばユーザーが
「うわ、入力項目多くてよくわかんね・・・」
「なんか面倒そう・・・、いいか」
といった感じで途中で離脱してしまってるかを取りたい場合は、 ユーザーがどの処理まで進めたかを知る必要があるためアプリケーション側で実装しないといけないこともあります。ただ、やりすぎても時間がかかってしまうので、本当に必要なところに必要な分だけ実装することをお勧めします。
ユーザーにアプローチできる手段の用意
データ上から想定したより使われていない場合、何が原因なのか仮設は立てると思いますが可能な限りユーザーに確認した方が良いです。 サービス提供者とユーザーの間では認識の違いは大きく、悲しいことに仮設が検討違いなことは非常によくあります・・・。 そのためアンケートなどでユーザーにアプローチできる手段を用意しておくと良いと思います。
おわりに
今回はアジャイル開発を支えるためのAWSを用いた運用(インフラの構成、監視、インデント対策、利用状況計測)についてお話しました。 これらが最初のリリース時に全て必要かというとそんなことはありません。当たるかどうか見えていないサービスとかであれば利用状況の計測が一番重要ですし、原価を抑えたいのであればサーバー1台からスタートするのも良いと思います。運用体制を作り、それをちゃんと回すのもコストがかかるので、サービスの成長に合わせて必要になった部分の体制を作っていくのが良いと思います。
一緒に働く仲間を募集しています。
新卒採用・中途採用を問わず、年間を通して、さまざまな職種を募集しています。「すぐに仕事がしたい」「話を聞いてみたい」「オフィスを訪問してみたい」など、ご応募をお待ちしています。共に未来をカタチにする仲間を待っています。





